
Documentation Needs a Feedback Loop
Checking documentation the moment code changes.

System diagrams, READMEs, API docs, design docs, knowledge bases, FAQs, PRDs, tutorials, runbooks, playbooks, etc. The list never ends, and neither does the maintenance burden.
Organizations live and die by documentation. Onboarding, compliance, decision-making, knowledge sharing, support. All of it assumes the docs are right.
They’re usually not.
Why?
Documentation fails for structural reasons. Shipping is visible and rewarded. Maintenance is quiet and thankless. Without enforcement, documentation updates are always optional, and optional work reliably loses.
The cost isn’t immediate. It surfaces later as slow onboarding, broken runbooks, support escalations, and repeated “How does this actually work?” conversations. By the time anyone notices, the gap between how the system works and how it’s described has already grown expensive to close.
Documentation drifts because nothing in the development process forces it to stay true.
Introducing Doc-Drift
If documentation drift is inevitable without enforcement, the fix has to live where enforcement already happens: the pull request. I built a project called Doc-Drift.
On every pull request, it compares the proposed code changes with the documentation and flags cases where the documentation now contradicts the code. Not hypothetically. Not stylistically. Only when a specific claim in the docs is no longer true, given the change being made.
That framing matters. Most documentation isn’t abstract guidance. It makes concrete claims: which commands exist, which endpoints are available, and which libraries are in use. Those claims are tightly coupled to the code, but we rarely verify that coupling when the code changes.
Doc-Drift treats documentation as a set of assertions that can be checked at the same time the system itself is under review. Instead of asking humans to remember to update docs, it turns documentation drift into a concrete, reviewable signal at pull-request time.
How it works
Essentially, I wired up a GitHub Action that does three things:
Reads the pull request diff
Checks those changes against documentation sources (e.g., a “docs” folder or an external URL to a document repository)
If drift exists, a Doc-Drift report is created and posted as a PR comment
Here’s the mental model:
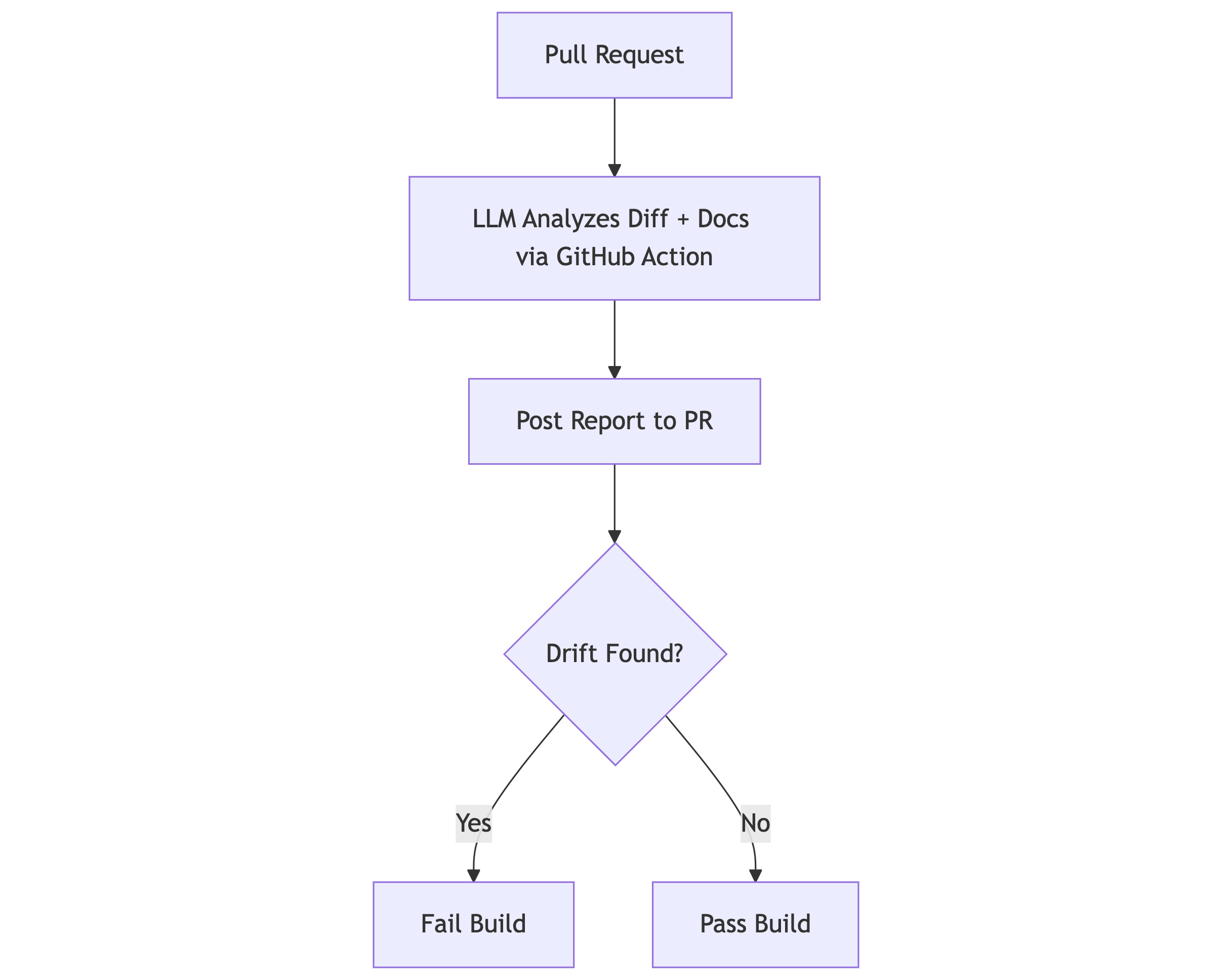
Here’s the most important constraint: the system is not allowed to guess.
No, “This might need review.”
If it can’t point to a specific code change and a specific piece of documentation that now conflicts with it, it stays silent.
This is a deliberate tradeoff. The system catches specific contradictions, not conceptual drift. It won’t notice a README that omits a new responsibility or guidance that’s become misleading without being false. I chose that constraint because LLMs confabulate, and a noisy tool is worse than no tool.
In other words, Doc-Drift is a starting point, not a complete solution. It catches obvious contradictions; subtler drift still requires human judgment.
See the full prompt.
False positives and cost
In practice, false positives in Doc-Drift have been rare. Maybe one in every dozen findings needs to be dismissed. On cost: I’m using GPT-4o-mini, which keeps things cheap. A typical PR with a moderately sized docs folder runs a fraction of a cent. Enough to leave running on every PR without thinking about it.
To gut-check this, I looked at my actual OpenAI usage data while testing Doc-Drift across many pull requests. The total spend reported was a whopping $0.03.
More expensive models and larger enterprise setups will cost more, but sub-cent checks at this baseline ain’t bad.
Context window limits
GPT-4o-mini has a 128k context window, which comfortably handles most documentation cases. For larger repositories, the action chunks documentation into smaller slices to stay within limits.
Chunking introduces an obvious risk: missing context or drawing incorrect conclusions from partial information. Doc-Drift avoids this by grounding every finding in quoted evidence from the same chunk being evaluated.
Findings
After experimenting with toy repos, I turned to Bulletproof React, a decently complex codebase with over 3,000 forks, extensive documentation, and non-trivial dependencies.
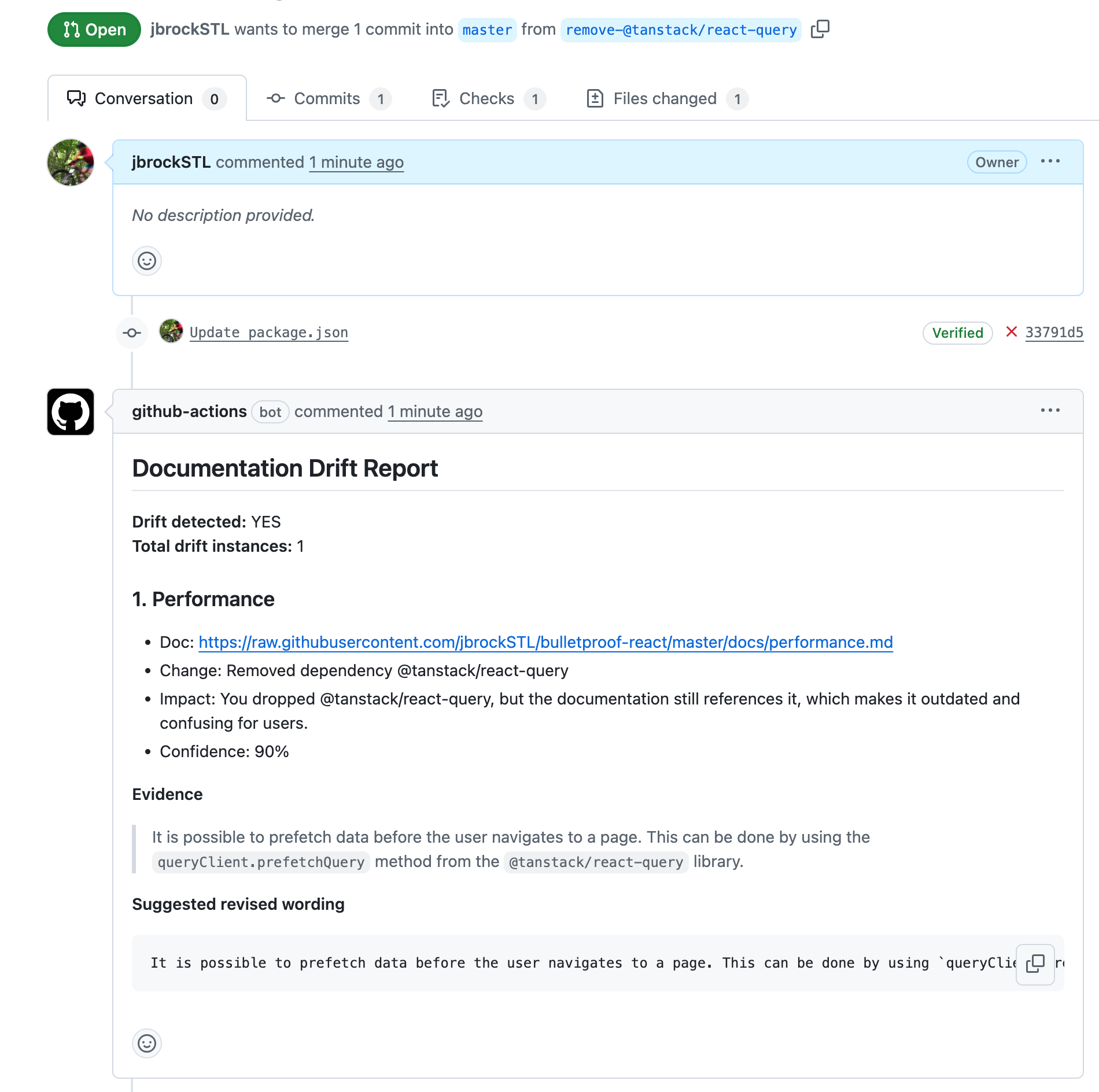
Test 1: Remove a dependency
I was happy to see that removing the dependency @tanstack/react-query (line 29) in package.json surfaced a reference in the performance doc.
The conflict surfaces verbatim as: “It is possible to prefetch data before the user navigates to a page. This can be done by using the queryClient.prefetchQuery method from the @tanstack/react-query library.” Without catching this drift, this guidance becomes useless the moment the PR merges. Worse, the build would likely break, or someone down the road might reintroduce the dependency without understanding why it was removed.
The suggested rewording seems weak: merely replacing @tanstack/react-query with “from a suitable data-fetching library.” I didn’t provide a replacement dependency in the PR, so maybe this is as good as we can expect. Hey, at least it doesn’t hit us with verbose best-practice nonsense.
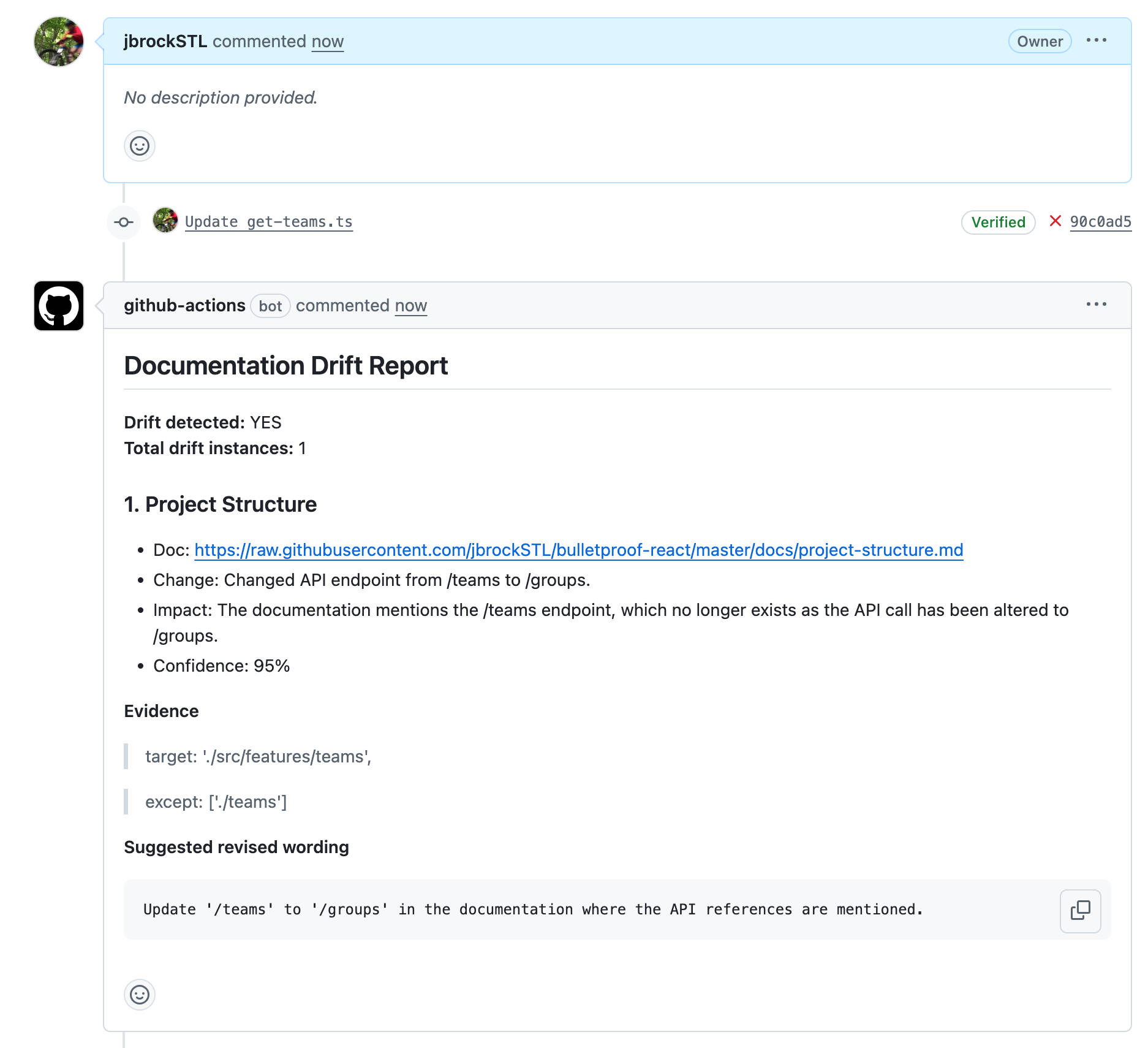
Test 2: Rename an endpoint
Renaming an endpoint in get-teams.ts (line 8) from /teams to /groups surfaced documentation drift in the project structure file. In this case, the LLM did a solid job, providing a clear impact statement and a suggested rewording that is about as good as you can reasonably expect.
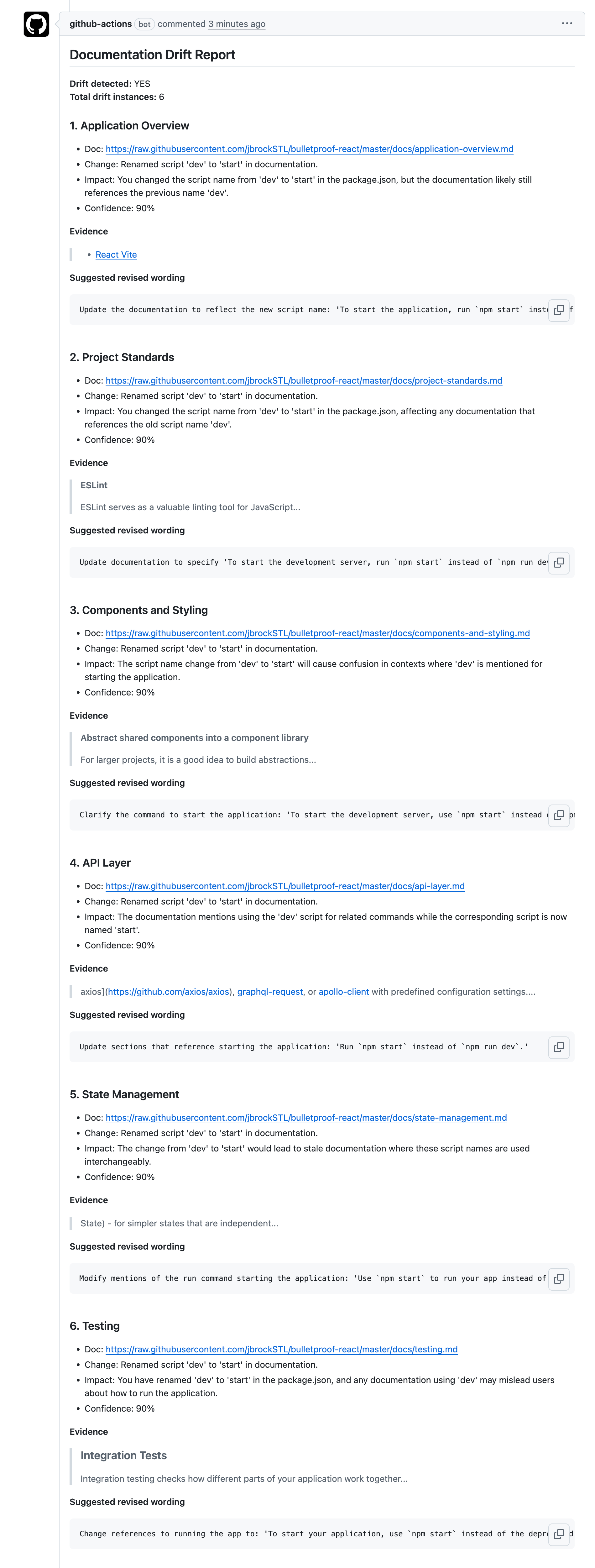
Test 3: Revise the startup command
I intentionally broke a startup command to see whether it was documented. In most projects, startup scripts usually are. The change itself was trivial: a single update to the Vite script (line 7):
"dev": "vite" → "start": "vite"The Doc-Drift report flagged roughly half a dozen documentation files, including Application Overview, Project Standards, State Management, and Testing, all of which still instruct readers to run npm run dev even though that command no longer exists. Once this change merges, each of those instructions becomes a dead end.
Where this could go
Missing Documentation
PR-time drift detection helps keep existing documentation honest. But it doesn’t answer: Where would new documentation add value?
Examples:
A new microservice with no README.
A new feature flag with no explanation of safety or removal.
A UI flow change that leaves the knowledge base pointing users to the wrong steps.
Once you start treating documentation as something that’s checked continuously rather than remembered occasionally, other LLM use cases come into focus.
Code Standards
The same PR-time feedback loop that catches documentation drift can also ask a nearby question:
Does this code change still reflect the standards we say we follow?
Most teams already have these written down somewhere:
architectural principles
design patterns
testing standards
secure coding guidelines
naming conventions
The opportunity is that code standards are rarely checked at the moment change happens, when the cost of feedback is lowest.
The question shifts from a post-hoc critique to a real-time prompt:
Has this part of the system evolved without explanation?
Does this change contradict how we say we build software here?
Final thought
Documentation will always lag behind the code. The question is by how much, and whether anyone notices before it gets too bad. Doc-Drift won’t close that gap entirely. But it shortens it automatically, on every PR. That’s a starting point worth having.
Try it yourself: Doc-Drift GitHub